
تعداد زیادی از مقالات دانشگاهی، اسناد تاریخی و سوابق رسمی تنها به صورت تصاویر اسکنشده وجود دارند؛ متون غیرقابل کپی هستند و ابزارهای استاندارد متنی قادر به پردازش آنها نیستند.
زمانی که پژوهش شما شامل استخراج نقلقولها، جداول یا مراجع از دهها فایل اینچنینی باشد، رونویسی دستی به یک مشکل جدی تبدیل میشود. موتورهای تشخیص نوری نویسهها (OCR) وجود دارند، اما اتصال و ادغام آنها در یک گردش کار (Workflow) هوش مصنوعیِ قابلاعتماد و تکرارپذیر اصلاً کار سادهای نیست: بیشتر خروجیهای خام OCR، تیترها را از دست میدهند، ستونها را با هم ادغام میکنند یا ساختار جداول را به هم میریزند؛ امری که استدلال و تحلیل سند را برای یک مدل زبانی بزرگ (LLM) با هرگونه اطمینانی غیرممکن میسازد.
شما به ابزاری نیاز دارید که نه تنها تصویر را بخواند، بلکه چیدمان منطقی (Logical Layout) سند را بازسازی کرده و متنی تمیز، ساختاریافته و سازگار با ماشین (Machine-friendly) را تحویل دهد. این دقیقاً همان کاری است که Docling برای انجام آن ساخته شده است.
Docling چه کاری انجام میدهد؟
Docling یک کتابخانه متنباز (Open-source) برای درک سند (Document Understanding) است که طیف وسیعی از فرمتهای سند را به اطلاعات ساختاریافتهای تبدیل میکند که کارگزاران هوش مصنوعی (AI Agents) میتوانند آنها را مصرف و پردازش کنند. Docling بسیار فراتر از یک پوسته و رابط ساده (Wrapper) برای OCR عمل میکند؛ این ابزار مستنداتی را پردازش میکند که در آنها متن، جداول و تصاویر با یکدیگر ترکیب شدهاند، از جمله چیدمانهای چندستونی، یادداشتهای دستنویس و PDFهای پیچیدهای که در واقع چیزی جز عکسهای اسکنشده نیستند. قابلیتهای کلیدی که Docling را متمایز میکند عبارتند از:
- درک محتوای ترکیبی: این ابزار اسنادی را مدیریت میکند که در آنها ترتیب خواندن طبیعی با جریان خام PDF مطابقت ندارد. جداول به صورت جدول باقی میمانند، تصاویر توضیحات (Captions) خود را حفظ میکنند و هدرها (Headers) به درون بدنه اصلی متن ریخته نمیشوند.
- انعطافپذیری در فرمت: این کتابخانه فرمتهای PDF، DOCX، PPT، XLSX، HTML، تصاویر (PNG، JPEG، TIFF)، LaTeX، متن ساده (Plain text)، WAV، MP3 و WebVTT را میپذیرد. این ویژگی به طرز چشمگیری دامنه مواد منبعی را که یک ایجنت هوش مصنوعی میتواند در مراحل بعدی (Downstream) با آنها کار کند، گسترش میدهد.
- یکپارچهسازی با MCP: از طریق پروتکل بافتار مدل (Model Context Protocol یا به اختصار MCP)، ابزار Docling به سرویسی تبدیل میشود که کارگزار شما میتواند آن را به طور مستقیم فراخوانی کند. این امر حلقه «بارگذاری > تبدیل > پرسوجو» را در یک گفتگوی واحد کامل میکند، بدون اینکه نیاز باشد رابط چت را ترک کنید.
به طور خلاصه، Docling عکس یک صفحه را میگیرد و آن را به یک فایل Markdown تبدیل میکند که ساختار واقعی محتوا را حفظ میکند. این ساختار همان چیزی است که تفاوت بین یک هوش مصنوعیِ ضعیف (که یک خلاصه به ظاهر معقول اما ساختگی تحویل میدهد) با هوش مصنوعیای که واقعاً به پاراگراف درست استناد میکند را رقم میزند.
ابزار Docling به لطف مدلهای پیشرفته تشخیص چیدمان (Layout Analysis) و ادغام با موتورهای OCR چندزبانه، قادر است اسناد فارسی را با دقت پردازش کند. این ابزار جهت متن را حفظ کرده، جداول راستبهچپ را به درستی تشخیص میدهد و اصطلاحات لاتین میان متن را مخدوش نمیکند.
نصب Docling به صورت محلی (Locally)
مراحل زیر از یک اِیجنت (Agent) در VS Code استفاده میکنند، اما همین رویکرد در هر محیطی که از MCP پشتیبانی کند نیز کارآمد است. ابتدا پنل چت اِیجنت خود را باز کنید.
اِیجنت های هوش مصنوعی مدرن اغلب میتوانند دستورالعملهای نصب را خودشان پیدا کرده و اعمال کنند. برای شروع، پرامپتی وارد کنید که دقیقاً آنچه را میخواهید توصیف کند:
Please help me install the Docling MCP service for use with an AI agent and configure the environment if necessary. For configuration, refer to the documentation at https://docling-project.github.io/docling/usage/mcp/
به محض اینکه اِیجنت تأیید کرد که پیکربندی کامل شده است، Docling آماده استفاده است.
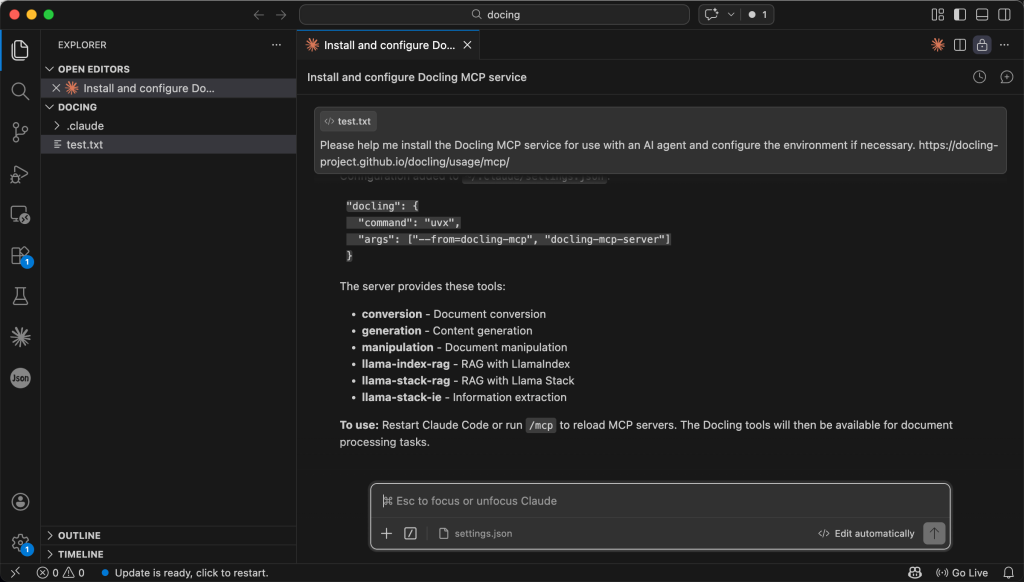
شما میتوانید با تایپ عبارت /mcp در کادر گفتگو، نصب را تأیید کنید. این کار فهرستی از تمام سرورهای MCP که در حال حاضر به اِیجنت شما متصل هستند را نمایش میدهد.
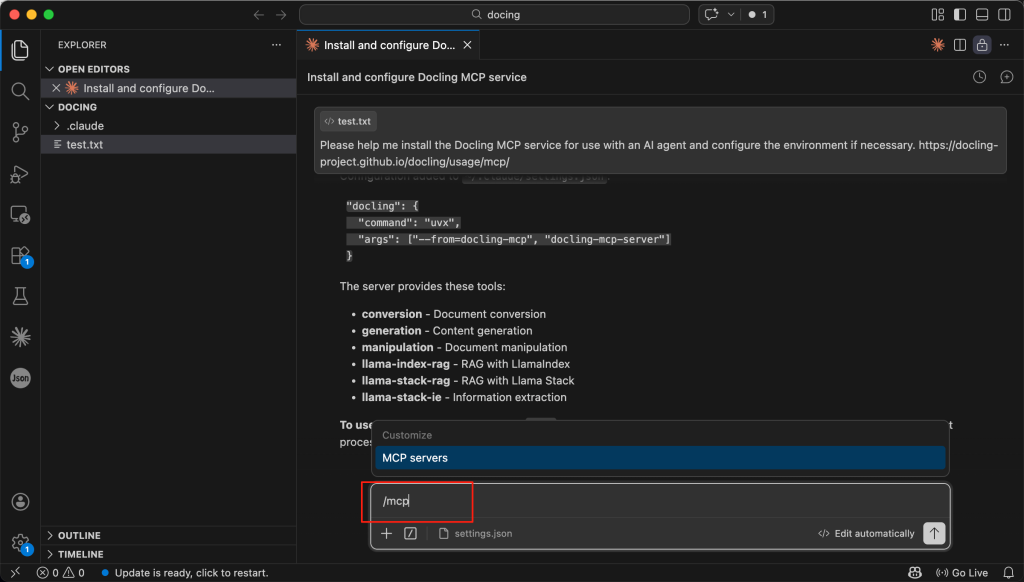
هنگامی که docling در لیست MCP ظاهر شد و وضعیت آن Connected بود (که معمولاً به رنگ سبز نشان داده میشود)، سرویس فعال است و منتظر درخواستهای شما میماند.
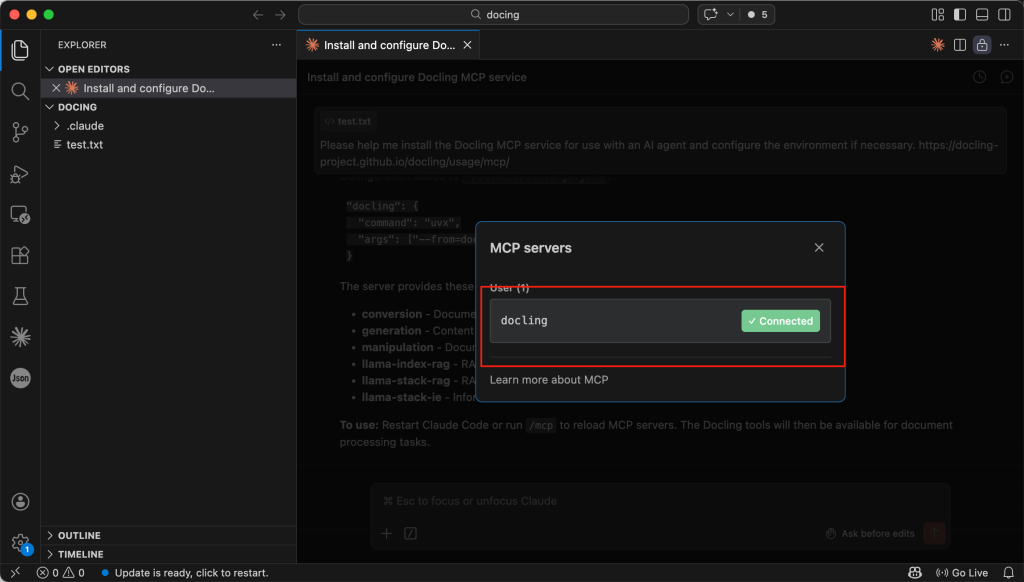
برای آزمایش راهاندازی، یک نمونه PDF اسکنشده را بارگذاری کرده و از اِیجنت بخواهید:
Please convert this PDF to Markdown.
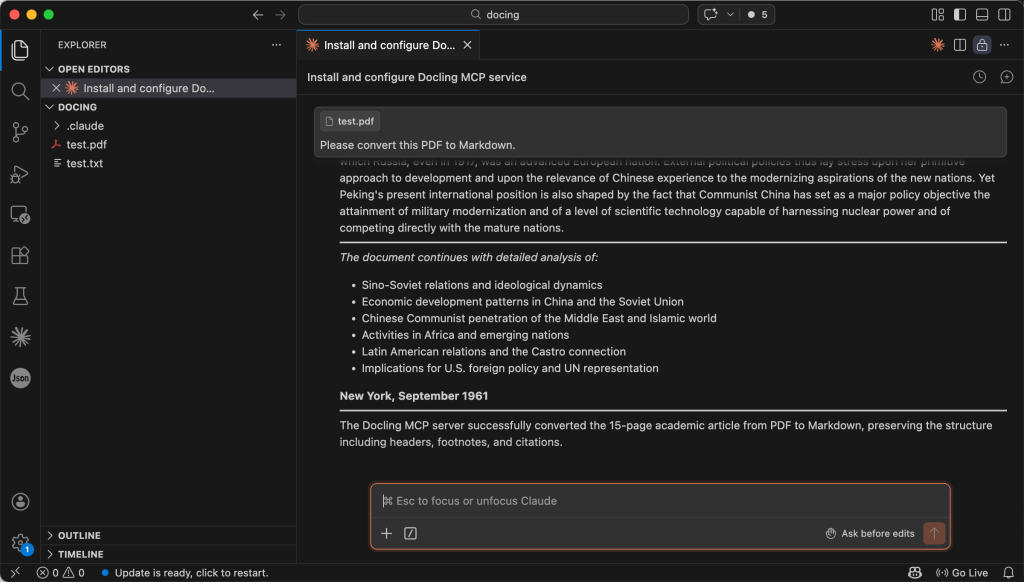
یک تبدیل موفقیتآمیز، خروجی تمیز و ساختاریافته Markdown را برمیگرداند که در آن عناوین، پاراگرافها، جداول و مراجع تصویری همگی حفظ شدهاند. این امر تأیید میکند که اِیجنت شما میتواند محتوای PDF را به طور قابلاعتمادی بخواند و پردازش کند، که این خود پایه و اساسی برای وظایف بعدی مانند خلاصهسازی، استخراج نکات کلیدی و پاسخدهی به سؤالات مبتنی بر شواهد (Evidence-grounded question answering) است.
اگر تبدیل با شکست مواجه شد یا خروجی نامفهوم و به هم ریخته به نظر رسید، از اِیجنت بخواهید که لاگها را بررسی کرده و اصلاحاتی را پیشنهاد دهد؛ راهحلهای رایج شامل تنظیم وابستگیهای سیستم (System Dependencies) یا اسکن مجدد PDF اصلی با رزولوشن بالاتر است.
بررسی کیفیت خروجی
بهدست آوردن یک فایل Markdown تنها نیمی از کار است. برای کارهای پژوهشیِ دقیق، باید تأیید کنید که خروجی به وفور و با امانتداری کامل، سند اصلی را بازنمایی میکند. چند دقیقه را صرف بررسی یک نمونه معرف کنید و به نکات زیر توجه ویژهای داشته باشید:
- یکپارچگی پاراگراف و ترتیب خواندن: بررسی کنید که پاراگرافهای کلیدی کامل باشند و با همان توالی منطقی موجود در PDF ظاهر شوند. چیدمانهای چندستونی گاهی اوقات موتورهای OCR را گیج میکنند، بنابراین به دنبال تکههای متنی باشید که ممکن است جابهجا شده باشند.
- صحت جداول (Table fidelity): تأیید کنید که جداول شناسایی شده و ساختار ستونی آنها حفظ شده است. جدولی که به صورت یک رشته تخت از اعداد رندر شده باشد، برای تحلیلهای بعدی تقریباً بیفایده است.
- فرمولهای ریاضی و کاراکترهای خاص: نمادها، حروف یونانی و معادلات بلوکی (Block equations) خطاپذیر هستند. بررسی کنید که آنها به درستی تبدیل شده باشند و مخدوش یا حذف نشده باشند.
- هدرها و فوترها (Headers and Footers): اطمینان حاصل کنید که عناوین جاری صفحات (Running heads)، شماره صفحات و پانویسها به اشتباه در متن اصلی ادغام نشده باشند، چرا که این امر محتوای استخراجشده را آلوده و مخدوش میکند.
برای اسناد بسیار مهم، ایمنترین کار این است که خروجی Markdown را صفحه به صفحه با PDF اصلی تطبیق دهید. اگر متوجه مشکلات سیستماتیک شدید، مانند فونتهای ناشناخته یا جداولی که به طور مداوم خراب میشوند، پیش از ارسال آن به Docling، سند را با DPI بالاتر مجدداً اسکن کنید یا فرمت خروجی دیگری را انتخاب کنید. اصلاحات کوچک در ورودی اغلب نتایج به طرز چشمگیری بهتری را به همراه دارد.
خلاصه
ابزار Docling محتوای اسکنشده و قفلشده را به Markdown ساختاریافته تبدیل میکند و شکاف میان اسناد استاتیک و پژوهشهای مبتنی بر هوش مصنوعی را پر میسازد. با پشتیبانی پیشفرض و آماده برای فرمتهای PDF، DOCX، PPT، XLSX، HTML، PNG، JPEG، TIFF، LaTeX، متن ساده، WAV، MP3 و WebVTT، این ابزار آشفتگی فرمتها را که معمولاً پروژههای سنگین و متکی بر اسناد را کند میکند، از بین میبرد. پس از نصب و تأیید سرویس MCP، میتوانید به سادگی هرگونه وظیفه تبدیل یا تحلیل را برای ایجنت خود توصیف کنید و اجازه دهید باقی کارها را خودش مدیریت کند.
بیشتر بخوانید:
استخراج متن با Snipping Tool در ویندوز ۱۱
نحوه استخراج متن از عکس در اندروید، ویندوز و آیفون
نصب و استفاده از Open WebUI: اجرای مدلهای زبانی هوش مصنوعی به صورت محلی



