
Web Crawler یک برنامه یا اسکریپت نرمافزاری است که به صورت خودکار صفحات وب را برای جمعآوری اطلاعات مرور میکند. این ابزار به سایتهای مختلف مراجعه میکند، لینکهای موجود در صفحات را دنبال میکند و محتویات آنها را دانلود یا بررسی میکند. Web Crawlerها به طور گسترده در موتورهای جستجو، مانند Google، برای ایندکسگذاری صفحات وب و بهبود رتبهبندی نتایج جستجو استفاده میشوند.
Web Crawlerها چگونه کار می کنند؟
Web Crawlerها، که به عنوان خزندههای وب یا عنکبوتهای وب نیز شناخته میشوند، به روشهای مختلفی برای جستجو، جمعآوری، و ایندکسگذاری اطلاعات از صفحات وب استفاده میکنند. در ادامه، فرآیند کار یک Web Crawler را به طور مرحله به مرحله توضیح میدهم:
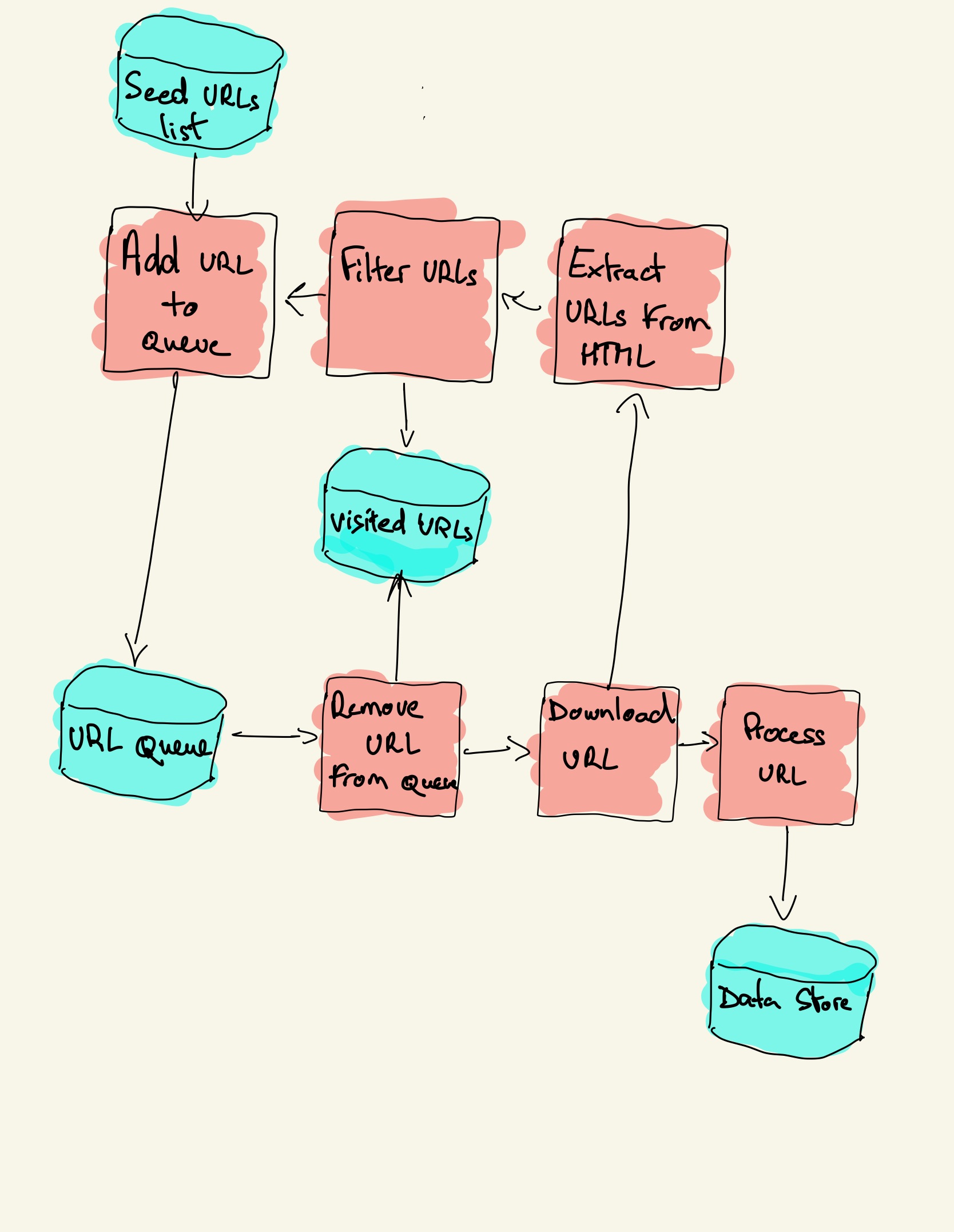
۱. شروع از URLهای اولیه (Seed URLs)
فرآیند خزیدن معمولاً با مجموعهای از URLهای اولیه آغاز میشود که به آنها Seed URLs گفته میشود. این URLها ممکن است توسط مدیران خزنده وب به طور دستی انتخاب شوند یا از منابع دیگری به دست آیند. این URLها به عنوان نقطه شروع عمل میکنند.
۲. دانلود صفحات وب
Web Crawler به هر یک از URLهای اولیه مراجعه میکند و محتوای صفحات وب را دانلود میکند. این محتوا شامل متن، تصاویر، لینکها، و سایر منابع موجود در صفحه است.
۳. استخراج لینکها
پس از دانلود یک صفحه، خزنده وب لینکهای موجود در آن صفحه را استخراج میکند. این لینکها شامل لینکهای داخلی (که به صفحات دیگری در همان سایت اشاره دارند) و لینکهای خارجی (که به سایتهای دیگر اشاره میکنند) هستند.
۴. اضافه کردن لینکهای جدید به صف خزیدن
لینکهای استخراج شده به صف خزیدن (Crawl Queue) اضافه میشوند. این صف یک لیست از URLهایی است که باید بعداً توسط خزنده بررسی شوند. خزنده ممکن است بر اساس اولویت یا سایر معیارها لینکها را از این صف انتخاب کند.
۵. تکرار فرآیند
خزنده وب به صورت مداوم لینکهای جدید را از صف خزیدن انتخاب کرده و مراحل دانلود، استخراج لینکها، و اضافه کردن آنها به صف را تکرار میکند. این فرآیند تا زمانی که خزنده به پایان کار برسد یا محدودیتهای زمانی و منابع به آن اجازه دهند ادامه مییابد.
۶. ایندکسگذاری محتوا
وقتی صفحهای توسط خزنده دانلود شد، محتوای آن به یک موتور ایندکسگذار (Indexer) ارسال میشود. این موتور محتوای صفحات را تحلیل کرده و آن را به شکلی سازماندهی میکند که برای جستجو توسط کاربران قابل استفاده باشد. این ایندکس به موتور جستجو کمک میکند تا در زمان انجام یک جستجو، نتایج مرتبط را به سرعت پیدا کند.
۷. مدیریت و بهروزرسانی خزیدن
خزندههای وب معمولاً به طور دورهای به سایتهای مختلف مراجعه میکنند تا محتوای جدید یا بهروز شده را پیدا کنند. این فرآیند به موتور جستجو کمک میکند تا همیشه آخرین نسخه از صفحات وب را در اختیار داشته باشد.
۸. رعایت محدودیتها
بسیاری از وبسایتها از طریق فایل robots.txt مشخص میکنند که کدام بخشهای سایت برای خزندهها مجاز هستند و کدام بخشها باید نادیده گرفته شوند. Web Crawlerها معمولاً به این محدودیتها احترام میگذارند.
۹. مدیریت منابع و کارایی
خزندههای وب باید به کارایی و مدیریت منابع توجه کنند. برای جلوگیری از بارگذاری بیش از حد سرورها و شبکهها، آنها باید بهینهسازیهای لازم را انجام دهند، مانند محدود کردن سرعت خزیدن یا استفاده از چندین خزنده موازی.
الگوریتمهای استفاده شده در Web Crawler
برای خزیدن مؤثر و کارآمد، Web Crawlerها از الگوریتمهای مختلفی استفاده میکنند:
- BFS (Breadth-First Search): در این روش، خزنده ابتدا تمام لینکهای یک صفحه را بازدید میکند و سپس به صفحات لینک شده از آنها میرود.
- DFS (Depth-First Search): در این روش، خزنده ابتدا به عمق یک شاخه از لینکها میرود و سپس به صفحات دیگر بازمیگردد.
- PageRank یا سایر الگوریتمهای رتبهبندی: برخی خزندهها از الگوریتمهای خاصی برای تعیین اولویت صفحات برای خزیدن استفاده میکنند.
چالشها و مشکلات
- محتوای دینامیک: برخی صفحات وب محتوای خود را با استفاده از جاوااسکریپت بهروز میکنند که خزیدن آنها را برای خزندهها پیچیده میکند.
- محتوای تکراری: تشخیص و مدیریت محتوای تکراری یک چالش بزرگ است.
- محدودیت خزیدن: بسیاری از وبسایتها به خاطر دلایل امنیتی یا حفظ منابع محدودیتهایی برای خزیدن اعمال میکنند.
در مجموع، Web Crawlerها نقش حیاتی در دسترسپذیری اطلاعات وب داشته و به موتورهای جستجو کمک میکنند تا نتایج دقیق و بهروز ارائه دهند.
نقش Robots.txt
فایل robots.txt یک فایل متنی است که در ریشه وبسایت قرار میگیرد و برای اطلاع رباتهای جستجو از طریق پروتکل خاصی به نام Robots Exclusion Protocol استفاده میشود. این فایل به رباتها (مانند گوگل باتها) میگوید که کدام بخشهای سایت را باید یا نباید این رباتها برای جستجو و ایندکس کردن بازدید کنند.
الزامات اصلی فایل robots.txt در Web Crawler شامل دستورات زیر میشوند:
- User-agent Directive: این دستور به رباتها نحوه برخورد با سایت را مشخص میکند. میتوانید از “*” برای اعمال یک دستور به همه رباتها استفاده کنید و یا از نام ربات خاصی مانند “Googlebot” برای محدود کردن دستور به یک ربات خاص استفاده کنید.
- Disallow Directive: این دستور به رباتها میگوید که کدام بخشهای سایت را نباید ایندکس کنند. برای مثال، Disallow: /private/ میگوید که رباتها باید از ایندکس کردن بخش private سایت خودداری کنند.
- Allow Directive: اگر بخواهید در مقابل Disallow مجوز دهید، از این دستور استفاده کنید. برای مثال، Allow: /public/ به رباتها اجازه میدهد تا بخش public سایت را ایندکس کنند.
- Sitemap Directive: این دستور به رباتها نشان میدهد که نقشه سایت (sitemap) سایت شما کجا قرار دارد.
- Crawl-delay Directive: این دستور میزان تأخیر بین درخواستهای رباتها برای دسترسی به صفحات سایت شما را تعیین میکند.
- Host Directive: این دستور به رباتها نشان میدهد که سایت شما در کدام دامنه میزبانی شده است.
این الزامات به کمک فایل robots.txt به وب کرالرها (Web Crawlers) اطلاعاتی ارائه میدهند که چگونه باید به سایت دسترسی پیدا کنند و صفحات را ایندکس کنند. احترام به این الزامات بهبود ایندکسبندی و نتایج جستجوی سایت شما را تضمین میکند.
Web Crawler چه کاربردی دارد؟
وبکرالر یا Web Crawler یک برنامه کامپیوتری است که به طور خودکار از طریق اینترنت صفحات وب را جستجو میکند، آنها را ایندکس میکند و اطلاعات مربوط به آنها را جمعآوری میکند. این اطلاعات برای موتورهای جستجو، محققان، شرکتهای تحقیقاتی، و سایر اهداف مفید هستند.
کاربردهای اصلی Web Crawler شامل:
- ایندکسبندی وبسایتها: وب کرالرها به موتورهای جستجو اجازه میدهند تا میلیونها صفحه وب را ایندکس کرده و به کاربران نتایج مرتبط با جستجوهایشان ارائه دهند.
- جمعآوری اطلاعات: از طریق جستجوی وب کرالرها میتوان اطلاعات مفیدی را از وبسایتها استخراج کرد. این اطلاعات میتواند برای تحقیقات بازاریابی، تحلیل رقبا، و یا هر دیگر هدف مورد نظر استفاده شود.
- پایش وبسایت: وب کرالرها میتوانند به مدیران وبسایتها کمک کنند تا به راحتی بفهمند که چگونه وبسایت آنها توسط موتورهای جستجو و رباتها مشاهده میشود.
- تحقیق در علوم داده: وب کرالرها میتوانند برای جمعآوری دادههای مورد نیاز برای تحلیل داده، یادگیری ماشین، یا هر برنامه دیگری که به داده نیاز دارد، مورد استفاده قرار گیرند.
- پیگیری تغییرات: وب کرالرها به مدیران وبسایتها کمک میکنند تا تغییرات در وبسایت خود را پیگیری کرده و مطمئن شوند که همه لینکها و صفحات به درستی کار میکنند.
وب کرالرها ابزار قدرتمندی برای جستجو و بهرهبرداری از اطلاعات وب هستند که در انواع حوزهها و صنایع از آنها استفاده میشود.
انواع Web Crawler
وبکرالرها، برنامههای کامپیوتری هستند که به صورت خودکار اطلاعات از صفحات وب را جمعآوری میکنند. این وبکرالرها برای انواع مختلفی از فعالیتها و استفادهها طراحی شدهاند. در زیر، برخی از انواع شایع وبکرالرها آورده شده است:
- وب کرالرهای عمیق (Deep Web Crawlers):
- این نوع وبکرالرها برای جستجو و دسترسی به اطلاعاتی که در صفحات وب عمیق و غیرقابل دسترس عمومی قرار دارند استفاده میشوند. آنها به طور معمول از سطحبندی عمیق و عمیقتر برای دسترسی به این اطلاعات استفاده میکنند.
- وب کرالرهای سطح (Surface Web Crawlers):
- این نوع وبکرالرها به جستجو و دسترسی به اطلاعاتی که در صفحات وب سطحی و قابل دسترس عمومی استفاده میشوند. آنها به طور اصطلاحی از سطحبندی سطحیتر برای دسترسی به اطلاعات استفاده میکنند.
- وب کرالرهای عمومی (General Purpose Web Crawlers):
- این نوع وبکرالرها برای جستجو و ایندکسبندی اطلاعات روی وب به صورت گسترده استفاده میشوند. آنها قابلیت جستجو در انواع مختلف صفحات وب را دارند.
- وب کرالرهای تخصصی (Focused Web Crawlers):
- این نوع وبکرالرها برای جستجوی اطلاعات در حوزههای خاص و تخصصی مورد استفاده قرار میگیرند. آنها به طور معمول بر روی موضوعات خاص یا دامنههای وب خاص تمرکز دارند.
- وب کرالرهای اختصاصی (Custom Web Crawlers):
- این نوع وبکرالرها برای نیازها و الگوهای خاص یک شرکت یا سازمان خاص طراحی و تنظیم میشوند. آنها به طور خاص برای موارد خاص مانند جمعآوری اطلاعات محصول، پایش رقبا و غیره استفاده میشوند.
هر کدام از این انواع وبکرالرها برای نیازها و اهداف خاص خود طراحی شدهاند و میتوانند در صنایع و زمینههای مختلف مورد استفاده قرار گیرند.
چگونه میتوان از وب کرالرها برای تحلیل رقبا استفاده کرد؟
استفاده از وب کرالرها برای تحلیل رقبا یک روش مؤثر برای درک بهتر بازار، رقبا و روند صنعتی است. در زیر چند مرحله برای استفاده از وب کرالرها برای تحلیل رقبا آورده شده است:
- انتخاب وب کرالر مناسب:
- برای شروع، شما نیاز به انتخاب یک وب کرالر مناسب دارید که قادر به جمعآوری دادههای مورد نظر شما از وبسایتها باشد. مثلاً میتوانید از وب کرالرهای رایگان یا پولی موجود در بازار استفاده کنید.
- تعیین هدف:
- قبل از شروع به استفاده از وب کرالرها برای تحلیل رقبا، باید هدف واضحی برای تحلیل دادهها خود داشته باشید. مشخص کنید که دقیقاً چه نوع اطلاعاتی نیاز دارید و چه معیارهایی برای تحلیل رقبایتان مهم است.
- تعیین رقبا:
- انتخاب رقبا و وبسایتهایی که میخواهید مورد تحلیل قرار دهید بسیار مهم است. انتخاب رقبا بازاریابی و تجاری خود را بهبود میبخشد.
- جمعآوری دادهها:
- اجرای وب کرالر بر روی وبسایتهای رقبا و جمعآوری دادههای مربوط به ترافیک وب، کلمات کلیدی، محتوا، و روند رقبا، از جمله قیمتها، تبلیغات، واکنشهای مشتریان و غیره.
- تحلیل دادهها:
- پس از جمعآوری دادهها، باید این دادهها را تحلیل کرده و الگوها، روندها و اطلاعات کلیدی را شناسایی کنید. میتوانید از ابزارهای تحلیل داده مختلف مانند Excel، Python، R و غیره استفاده کنید.
- بررسی وضعیت رقبا:
- با تحلیل دادههای جمعآوری شده، میتوانید وضعیت رقبا، نقاط ضعف و قوت آنها را شناسایی کرده و بهترین راهکارها برای بهبود رقابت خود را پیدا کنید.
استفاده از وب کرالرها برای تحلیل رقبا به شما کمک میکند تا اطلاعات بیشتری در مورد بازار، مصرفکنندگان، و رقبا خود داشته باشید و تصمیمات بهتری برای بهبود راهبرد تجاری خود بگیرید.
مقایسه Web Crawling و Web Scraping
تفاوت اصلی بین Web Crawling و Web Scraping در اهداف و روشهای آنهاست. Web Crawling فرآیند جمعآوری و جستجوی صفحات وب به منظور ساخت یک نقشه یا ایندکس از محتوای وبسایتها است، که معمولاً توسط موتورهای جستجو مانند گوگل انجام میشود.

این فرآیند به طور مداوم و خودکار صفحات جدید و بهروزرسانیهای محتوا را شناسایی میکند. از طرف دیگر، Web Scraping به استخراج دادههای خاص از صفحات وب اشاره دارد، که معمولاً با استفاده از ابزارها یا برنامههای خاص برای جمعآوری اطلاعات ساختاریافته از یک یا چند صفحه انجام میشود. در نتیجه، Crawling برای ایجاد نقشهای جامع از وب و Scraping برای استخراج دادههای خاص و هدفمند استفاده میشود.
آیا Web Crawler روی سئو تاثیر دارد؟
وب کراولرها روی سئو (بهینهسازی موتورهای جستجو) تاثیر دارند. وب کراولرها یا رباتهای موتورهای جستجو مانند گوگلبات، صفحات وب را بررسی میکنند تا محتوای آنها را فهرستبندی کنند و در نتایج جستجو نمایش دهند. اگر وبسایت شما برای کراولرها بهینهسازی نشده باشد، ممکن است صفحات شما به درستی فهرستبندی نشوند و در نتیجه در نتایج جستجو به خوبی ظاهر نشوند.
نکات مهمی که باید در نظر گرفته شوند شامل موارد زیر است:
- ساختار سایت: یک ساختار سایت منطقی و قابل دسترس به کراولرها کمک میکند تا به راحتی به تمامی صفحات دسترسی پیدا کنند.
- فایل robots.txt: این فایل به کراولرها میگوید کدام بخشهای سایت را باید یا نباید کراول کنند. تنظیم نادرست این فایل میتواند منجر به عدم فهرستبندی برخی صفحات مهم شود.
- نقشه سایت (XML Sitemap): نقشه سایت به موتورهای جستجو کمک میکند تا تمامی صفحات مهم سایت شما را پیدا کنند و آنها را فهرستبندی کنند.
- سرعت بارگذاری صفحات: سرعت بارگذاری صفحات نیز میتواند تاثیر گذار باشد چون موتورهای جستجو به سرعت بارگذاری صفحات اهمیت میدهند.
- لینکهای داخلی و خارجی: ساختار لینکهای داخلی و خارجی باید به گونهای باشد که دسترسی به صفحات مهم سایت را برای کراولرها آسان کند.
- محتوا و متا تگها: استفاده از کلمات کلیدی مناسب و متا تگهای بهینه شده نیز به کراولرها کمک میکند تا موضوع صفحه شما را بهتر درک کنند.
با رعایت این اصول، میتوانید اطمینان حاصل کنید که وبسایت شما به درستی توسط وب کراولرها فهرستبندی میشود و در نتایج جستجو رتبه بهتری کسب میکند.
آموزش بلاک کردن Web Crawler از روی سایت
بلاک کردن وب کراولرها از دسترسی به سایت شما میتواند در مواردی مفید باشد، مثلاً وقتی نمیخواهید محتوای خاصی از سایت شما در موتورهای جستجو فهرستبندی شود. این کار معمولاً با استفاده از فایل robots.txt انجام میشود. در زیر مراحل ایجاد و تنظیم فایل robots.txt برای بلاک کردن وب کراولرها آورده شده است:
۱. ایجاد فایل robots.txt
ابتدا یک فایل متنی با نام robots.txt ایجاد کنید. این فایل باید در دایرکتوری ریشهی وبسایت شما قرار گیرد (مثلاً http://www.example.com/robots.txt).
۲. تنظیمات بلاک کردن
در فایل robots.txt، میتوانید با استفاده از دستورات زیر وب کراولرها را بلاک کنید:
بلاک کردن تمامی کراولرها از دسترسی به کل سایت:
User-agent: *
Disallow: /
این دستور به تمامی وب کراولرها میگوید که هیچ بخشی از سایت شما را نباید کراول کنند.
بلاک کردن کراولر خاص:
اگر میخواهید یک کراولر خاص (مثلاً گوگلبات) را بلاک کنید، میتوانید از دستور زیر استفاده کنید:
User-agent: Googlebot
Disallow: /
این دستور فقط گوگلبات را از دسترسی به کل سایت شما منع میکند.
بلاک کردن دسترسی به یک بخش خاص از سایت:
اگر میخواهید دسترسی به یک بخش خاص از سایت را برای تمامی کراولرها یا یک کراولر خاص محدود کنید، میتوانید از دستورات زیر استفاده کنید:
User-agent: *
Disallow: /private/
این دستور تمامی کراولرها را از دسترسی به دایرکتوری /private/ منع میکند.
۳. بارگذاری فایل robots.txt روی سرور
پس از ایجاد و تنظیم فایل robots.txt، آن را در دایرکتوری ریشهی سایت خود بارگذاری کنید.
۴. تست و بررسی
برای اطمینان از اینکه فایل robots.txt به درستی کار میکند، میتوانید از ابزارهای مختلفی مانند “Robots.txt Tester” در Google Search Console استفاده کنید. این ابزار به شما کمک میکند تا بررسی کنید آیا تنظیمات فایل robots.txt شما به درستی اعمال شدهاند یا خیر.
مثال کامل از فایل robots.txt
# بلاک کردن تمامی کراولرها از دسترسی به دایرکتوری /private/
User-agent: *
Disallow: /private/
# بلاک کردن گوگلبات از دسترسی به کل سایت
User-agent: Googlebot
Disallow: /
# اجازه دادن به تمامی کراولرها برای دسترسی به بقیه سایت
User-agent: *
Allow: /
با تنظیمات مناسب در فایل robots.txt میتوانید کنترل دقیقی بر روی دسترسی وب کراولرها به بخشهای مختلف سایت خود داشته باشید.
توانیی Web Crawlerها در بررسی عکس و ویدئو
وب کراولرها میتوانند اطلاعات مربوط به تصاویر و ویدیوها را بخوانند، اما نحوه پردازش و درک محتوای این نوع فایلها با محتوای متنی متفاوت است. در زیر به توضیح بیشتری درباره این موضوع میپردازیم:
۱. تصاویر
وب کراولرها میتوانند تصاویر را شناسایی کنند و اطلاعات مربوط به آنها را از تگهای HTML استخراج کنند. موارد زیر در این فرآیند اهمیت دارند:
- تگ
alt: متن جایگزین (alt text) برای تصاویر بسیار مهم است. این متن به کراولرها کمک میکند تا محتوای تصویر را درک کنند. به عنوان مثال:<img src="example.jpg" alt="تصویری از یک منظره طبیعی"> - نام فایل و مسیر: نام فایل تصویر و مسیر ذخیرهسازی آن نیز مورد توجه کراولرها قرار میگیرد. استفاده از نامهای توصیفی و مرتبط با محتوا میتواند مفید باشد.
- تگهای
titleوcaption: این تگها نیز میتوانند به توصیف محتوای تصویر کمک کنند.
۲. ویدیوها
وب کراولرها میتوانند اطلاعات مربوط به ویدیوها را نیز بخوانند، اما برای درک محتوای ویدیوها نیاز به اطلاعات متنی بیشتری دارند. موارد زیر میتوانند به بهبود فهرستبندی ویدیوها کمک کنند:
- تگهای متا و توضیحات: استفاده از تگهای متا و توضیحات مرتبط با ویدیو میتواند به کراولرها کمک کند تا موضوع و محتوای ویدیو را بهتر درک کنند.
<video controls> <source src="example.mp4" type="video/mp4"> Your browser does not support the video tag. </video> <p>توضیحاتی درباره این ویدیو که موضوع آن را شرح میدهد.</p> - زیرنویسها و متنهای همراه: استفاده از زیرنویسها و ارائه متنهای همراه با ویدیو میتواند به درک بهتر محتوای ویدیو کمک کند.
- استفاده از پلتفرمهای ویدیویی مانند YouTube: پلتفرمهایی مانند YouTube ابزارها و امکاناتی برای بهینهسازی سئو ویدیو فراهم میکنند، از جمله افزودن عنوان، توضیحات، تگها و زیرنویسها.
نکات اضافی:
- نقشه سایت تصاویر و ویدیوها: شما میتوانید نقشه سایت جداگانهای برای تصاویر و ویدیوها ایجاد کنید و این نقشهها را به فایل
robots.txtخود اضافه کنید. این کار به موتورهای جستجو کمک میکند تا به راحتی به این نوع محتوا دسترسی پیدا کنند. - فرمتهای بهینه: استفاده از فرمتهای بهینه برای تصاویر (مانند JPEG و PNG) و ویدیوها (مانند MP4) میتواند به بهبود سرعت بارگذاری و همچنین بهبود سئو کمک کند.
با رعایت این نکات، میتوانید اطمینان حاصل کنید که وب کراولرها به درستی تصاویر و ویدیوهای شما را شناسایی و فهرستبندی میکنند.
جمع بندی:
در این مقاله به اهمیت وب کراولرها و تاثیر آنها بر سئو پرداختیم و توضیح دادیم که چگونه تنظیمات صحیح در فایل robots.txt میتواند دسترسی کراولرها به بخشهای مختلف سایت را کنترل کند. همچنین به روشهای بهینهسازی تصاویر و ویدیوها برای موتورهای جستجو اشاره کردیم. با رعایت نکاتی مانند استفاده از تگهای alt برای تصاویر، افزودن توضیحات متنی به ویدیوها و ایجاد نقشه سایت جداگانه برای محتوای چندرسانهای، میتوانید اطمینان حاصل کنید که محتوای سایت شما به درستی فهرستبندی شده و در نتایج جستجو به خوبی نمایش داده میشود. این اقدامها نه تنها به بهبود رتبه سایت شما در موتورهای جستجو کمک میکنند، بلکه تجربه کاربری بهتری نیز برای بازدیدکنندگان فراهم میآورند.



