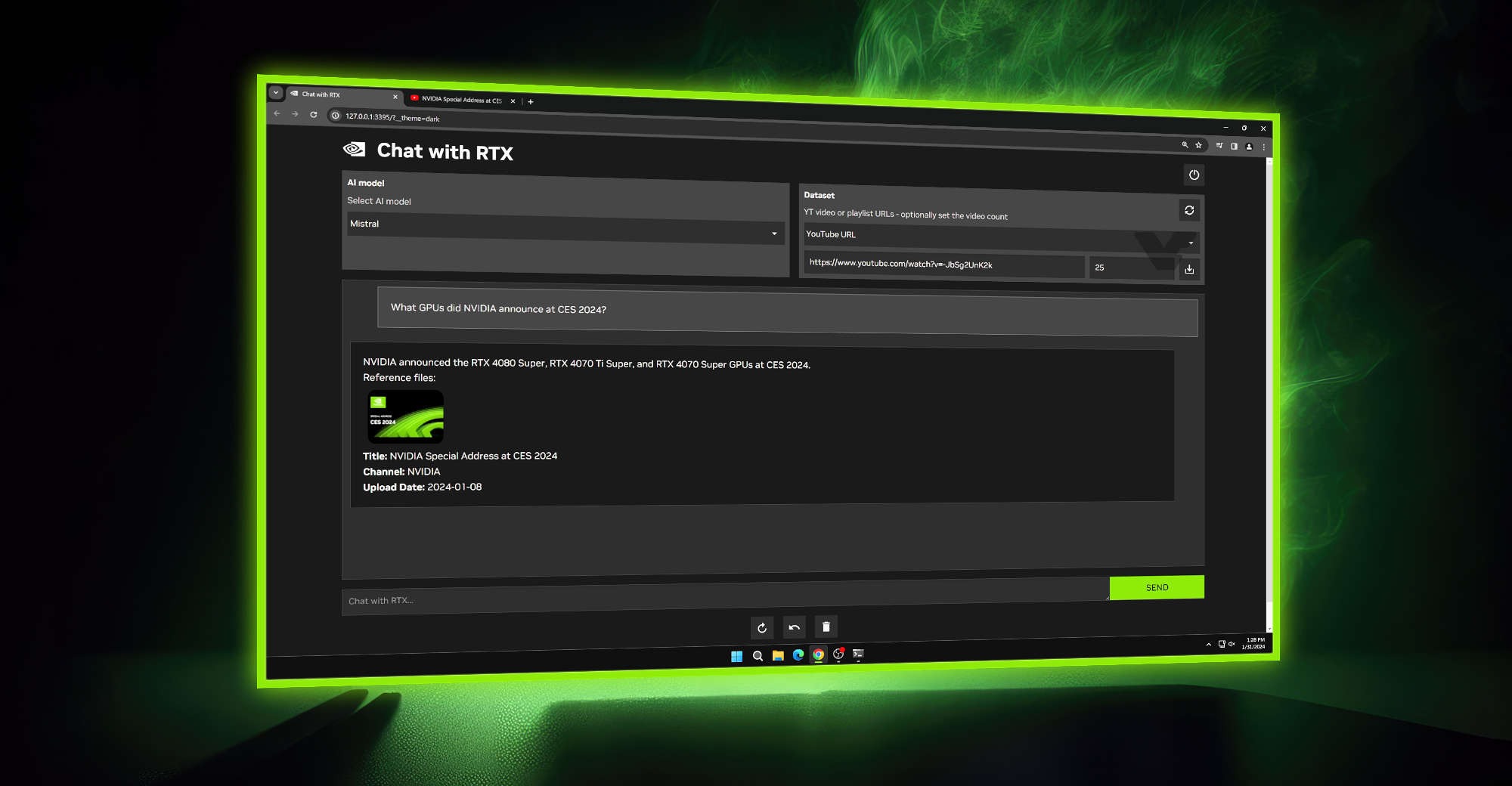
چت بات انویدیا یعنی NVIDIA Chat with RTXI AI Chatbot مرز جدیدی در تعامل با کاربر ارائه داده است. این ابزار نوآورانه که برای آسانتر کردن کارها برای کاربران طراحی شده است، از هوش مصنوعی و فناوری RTX NVIDIA برای ارائه دستیار هوش مصنوعی خود استفاده میکند. در این مقاله نکات استفاده از NVIDIA Chat with RTXI AI Chatbot را در ویندوز بررسی می کنیم و پتانسیل کامل آن را باز می کنیم.
NVIDIA Chat with RTXI AI Chatbot چیست؟
Chat with RTX یک نسخه دمو فناورانه است که از پردازنده گرافیکی NVIDIA GeForce RTX 30 یا یک مدل برتر با حداقل ۸ گیگابایت VRAM استفاده می کند تا کاربران را با یک چت بات سفارشی توانمند کند. اگر در مورد تفاوت بین ChatGPT و Chat with RTX میپرسید، باید بگوییم دومی یک چت ربات هوش مصنوعی است که روی TensorRT-LLM و RAG اجرا میشود در حالی که اولی روی معماری GPT کار میکند.
کاری که TensorRT-LLM انجام میدهد این است که پاسخها را به سرعت تولید میکند و امکان سفارشیسازی بیشتر پاسخها را فراهم میکند، و با RAG ، کاربران میتوانند انتظار داشته باشند که چت بات نه تنها پاسخها را تولید کند، بلکه اطلاعات را از دیتابیس یا منابع خارجی بازیابی کند، در حالی که ChatGPT فاقد این ویژگی هاست.
از NVIDIA Chat with RTXI AI Chatbot در کامپیوتر ویندوزی خود استفاده کنید
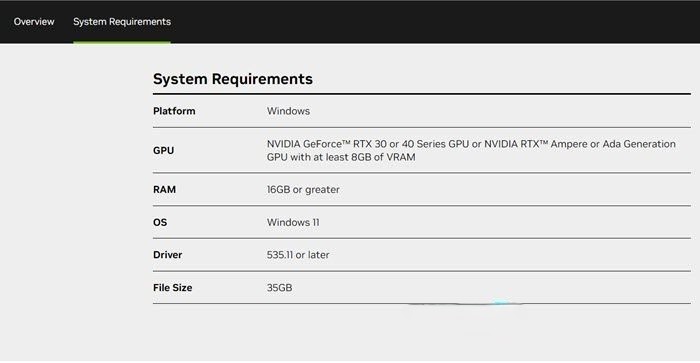
انویدیا اجرای LLM را به صورت محلی بر روی کامپیوتر شما بسیار آسان کرده است. برای اجرای Chat with RTX، فقط باید برنامه را دانلود و نصب کنید، درست مانند هر نرم افزار دیگری. با این حال، Chat with RTX دارای حداقل مشخصات لازم برای نصب و استفاده صحیح است.
- پردازنده گرافیکی RTX سری ۳۰ یا سری ۴۰
- ۱۶ گیگابایت رم
- ۱۰۰ گیگابایت فضای ذخیره سازی آزاد
- ویندوز ۱۱
در صورتی که تمام پیش نیازها را دارید، اجازه دهید برنامه را نصب کنیم. در اینجا نحوه انجام آن آمده است:
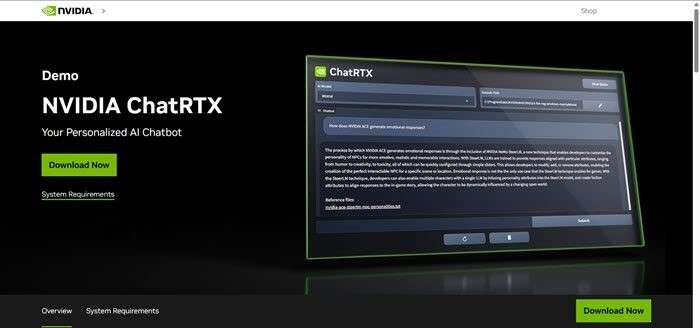
قبل از اقدام به دانلود، مطمئن شوید که اینترنت پایدار است و سپس با کلیک بر روی دکمه Download Now، فایل زیپ Chat with RTX را از nvidia.com دانلود کنید.
حال روی فایل مورد نظر راست کلیک کرده و آن را استخراج کنید. حالا به فایل setup بروید و برای نصب دو بار کلیک کنید.
تمام دستورات نصب را دنبال کنید و تمام کادرها را علامت بزنید و سپس دکمه Next را فشار دهید. این امر دانلود و نصب خودکار LLM را به همراه تمام فایل های لازم تضمین می کند.
نصب Chat with RTX مدتی طول می کشد تا به پایان برسد زیرا حجم زیادی از داده را دانلود و نصب می کند. پس از اتمام مراحل نصب، Close را بزنید. اکنون زمان آن رسیده است که برنامه را امتحان کنید.
از NVIDIA Chat with RTX استفاده کنید
پس از اتمام مراحل نصب، نوبت به سفارشی سازی و استفاده از آن می رسد. در حالی که Chat with RTX می تواند به عنوان یک چت بات آنلاین استاندارد هوش مصنوعی عمل کند، اما شدیدا پیشنهاد میکنیم عملکرد RAG آن را بررسی کنید. این به ما امکان میدهد پاسخ را مطابق با دسترسیهایی که به محتوای خاص میدهیم تنظیم کنیم و تطبیقپذیری را افزایش دهیم، در اینجا نحوه انجام آن آمده است:
۱- یک پوشه RAG بسازید
برای شروع استفاده از RAG در چت با RTX، یک پوشه جدید برای ذخیره فایلهایی که میخواهید هوش مصنوعی تجزیه و تحلیل کند ایجاد کنید.
پس از ایجاد، فایل های داده خود را در پوشه قرار دهید. دادههایی که ذخیره میکنید میتوانند موضوعات و انواع فایلهای زیادی مانند اسناد، فایلهای PDF، متن و ویدیوها را پوشش دهند. با این حال، ممکن است بخواهید تعداد فایلهایی را که در این پوشه قرار میدهید محدود کنید تا بر عملکرد تأثیری نگذارد. داده های بیشتر به این معنی است که زمان برای بازگرداندن پاسخ بیشتر طول می کشد (اما این نیز وابسته به سخت افزار است).
این پوشه مانند یک دیتابیس عمل می کند که ChatRTX از آن ورودی دریافت می کند.
۲- نصب محیط
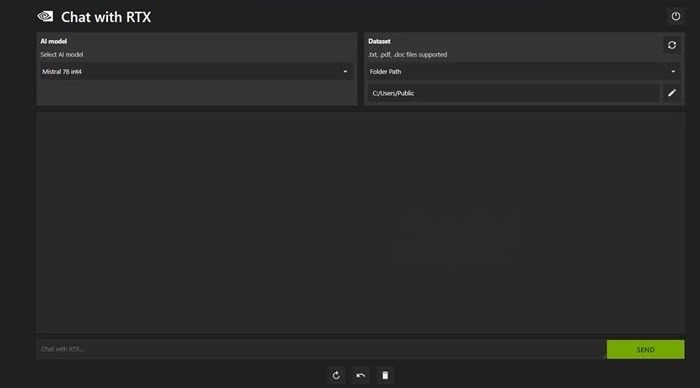
پس از تنظیم فرآیند اولیه، به تب Dataset رفته و به گزینه Folder Path رفته و سپس بر روی آیکون Edit کلیک کنید. حالا پوشه ای را که می خواهید هوش مصنوعی بخواند به همراه مدل هوش مصنوعی انتخاب کنید. هنگامی که دیتابیس سازماندهی شد، از هوش مصنوعی برای رسیدگی به سوالات و درخواست ها استفاده کنید.
۳- از هوش مصنوعی سوال های خود را بپرسید
پس از تمام موارد عملی، اکنون میتوانیم سؤالات و درخواستهای خود را از Chat with RTX بپرسیم. ما می توانیم از آن به عنوان یک چت بات معمولی هوش مصنوعی یا به عنوان دستیار هوش مصنوعی شخصی استفاده کنیم. اولی به سوالات پاسخ می دهد در حالی که دومی می تواند داده ها را از فایل هایی مانند PDF برگرداند. با این حال، تنها در صورتی امکان پذیر است که فایل های داده و تاریخ های تقویم را به روز نگه داریم.
علاوه بر این، ویژگی RAG Chat with RTX همچنین میتواند اسناد را خلاصه کند، کدهایی را برای کارهای برنامهنویسی تولید کند، نکات کلیدی را برای ویدیوها استخراج کند، و ویدیوهای یوتیوب را به سادگی با جای گذاری لینک ویدیو در محل های تعیینشده تجزیه و تحلیل کند.
آیا می توانید از چت بات با پردازنده گرافیکی RTX استفاده کنید؟
بله، چت بات ها می توانند از یک GPU RTX برای بهبود عملکرد و کارایی استفاده کنند. یک GPU RTX وظایف مربوط به پردازش زبان طبیعی (NLP) را تسریع میکند، میتواند مجموعه دادههای بزرگتری را مدیریت کند، مدلهای پیچیدهتری را اجرا کند و پاسخهای سریعتری ارائه دهد. علاوه بر این، پردازندههای گرافیکی RTX میتوانند کارهایی مانند تشخیص و تولید گفتار در زمان واقعی را تسهیل کنند و قابلیتهای مکالمه یک ربات چت را بیشتر کنند.
آیا Chat with RTX عملکرد خوبی دارد؟
ChatGPT ویژگی RAG را ارائه می دهد. برخی از چت بات های هوش مصنوعی لوکال هم به میزان قابل توجهی نیازمندیهای سیستمی پایینتری دارند. بنابراین، آیا چت انویدیا با RTX حتی ارزش استفاده دارد؟
پاسخ بله است! ارزش استفاده دارد.
یکی از بزرگترین نقاط قوت استفاده از NVIDIA Chat with RTXI AI Chatbot، توانایی آن در استفاده از RAG بدون ارسال فایلهای شما به سرور شخص ثالث است. سفارشی کردن GPT ها از طریق خدمات آنلاین می تواند داده های شما را در معرض دید قرار دهد. اما از آنجایی که Chat with RTX به صورت محلی و بدون اتصال به اینترنت اجرا میشود، استفاده از RAG در Chat with RTX تضمین میکند که دادههای حساس شما ایمن هستند و فقط در سیستم شخصی شما قابل دسترسی هستند.
همانند سایر رباتهای چت هوش مصنوعی محلی که Mistral 7B را اجرا میکنند، Chat with RTX بهتر و سریعتر عمل میکند. اگرچه بخش بزرگی از افزایش عملکرد ناشی از استفاده از پردازندههای گرافیکی سطح بالاتر است، استفاده از Nvidia TensorRT-LLM و شتاب RTX باعث شد اجرای Mistral 7B در Chat with RTX در مقایسه با سایر روشهای اجرای یک LLM بهینه شده برای چت، سریعتر شود.
شایان ذکر است که نسخه Chat with RTX که در حال حاضر از آن استفاده می کنیم یک نسخه آزمایشی است. نسخههای بعدی Chat with RTX احتمالاً بهینهتر شده و عملکرد را افزایش میدهد.
اگر پردازنده گرافیکی سری RTX 30 یا ۴۰ نداشته باشم چه می شود؟
Chat with RTX یک راه آسان، سریع و ایمن برای اجرای LLM به صورت محلی بدون نیاز به اتصال به اینترنت است. اگر شما نیز علاقه مند به اجرای LLM یا محلی هستید اما پردازنده گرافیکی سری RTX 30 یا ۴۰ ندارید، می توانید راه های دیگری را برای اجرای LLM به صورت محلی امتحان کنید. دو مورد از محبوب ترین آنها GPT4ALL و Text Gen WebUI هستند. اگر می خواهید یک تجربه plug-and-play به صورت محلی در حال اجرای LLM داشته باشید، GPT4ALL را امتحان کنید.
بیشتر بخوانید:
نحوه دانلود و نصب Fooocus | تولید تصویر هوش مصنوعی رایگان و آفلاین
نحوه استفاده از هوش مصنوعی بینگ برای ساخت تصویر
جستجوی عمیق بینگ چیست و چگونه کار می کند؟



