
کتابخانه Scikit-Learn یک کتابخانه متنباز، مفید، پرکاربرد و قدرتمند در زبان برنامهنویسی پایتون است که برای اهداف یادگیری ماشین استفاده میشود. این کتابخانه به منظور یادگیری ماشین و مدلسازی آماری دادهها، ابزارهای کاربردی زیادی ارائه میدهد، از جمله طبقهبندی، رگرسیون، خوشهبندی و کاهش ابعاد. طراحی این کتابخانه اساساً بر پایهی کتابخانههای NumPy، SciPy و Matplotlib صورت گرفته است و به طور گسترده از زبان پایتون بهره میبرد.
در اینجا، ما قصد داریم به آموزش کتابخانه Scikit-Learn بپردازیم. آموزش Scikit-Learn میتواند برای افرادی که به یادگیری علم داده علاقهمند هستند، بسیار مفید باشد. همچنین، در اینجا نحوهی پیادهسازی SVM در Scikit-Learn را مشاهده خواهیم کرد. با ما همراه باشید.
آموزش نصب Scikit-Learn
برای نصب کتابخانه Scikit-Learn در Python، میتوانید از مدیر بسته pip استفاده کنید. دستور زیر را در ترمینال یا پنجره دستورات سیستم عامل خود اجرا کنید:
pip install scikit-learnاین دستور Scikit-Learn را به همراه تمامی وابستگیهای لازم برای آن نصب خواهد کرد. توصیه میشود از طریق محیط مجازی Python این عملیات را انجام دهید تا تداخل با بستههای دیگر موجود در سیستم جلوگیری شود.
بعد از نصب موفقیتآمیز، میتوانید Scikit-Learn را در برنامههای Python خود وارد کنید با استفاده از دستور زیر:
import sklearnبا اجرای این دستور، کتابخانه Scikit-Learn آماده استفاده خواهد بود و میتوانید از توابع و امکانات آن استفاده کنید.
Scikit-Learn چه ویژگی های دارد؟
Scikit-Learn یکی از کتابخانههای محبوب و قدرتمند در زمینه یادگیری ماشین و تحلیل داده در زبان برنامهنویسی Python است. این کتابخانه دارای ویژگیها و قابلیتهای متنوعی است که آن را به یک ابزار کاربردی برای توسعه الگوریتمهای یادگیری ماشین و تحلیل داده تبدیل کرده است. در زیر به برخی از ویژگیهای مهم Scikit-Learn اشاره میکنم:
- سادگی و قابلیت استفاده: Scikit-Learn با رویکردی ساده و مستقیم طراحی شده است. رابط کاربری یکنواخت و مستندسازی کامل آن، کار با آن را برای توسعهدهندگان آسان و قابل فهم میکند.
- پوشش گسترده الگوریتمی: Scikit-Learn شامل مجموعهای گسترده از الگوریتمهای یادگیری ماشین است که شامل الگوریتمهای مدلسازی، تجزیه و تحلیل داده، کاهش بعد، خوشهبندی و غیره میشود. این کتابخانه به شما امکان توسعه و آزمایش با انواع الگوریتمهای یادگیری ماشین را میدهد.
- سازگاری با کتابخانههای دیگر: Scikit-Learn با کتابخانههای محبوب دیگری مانند NumPy (برای عملیات عددی)، Pandas (برای تحلیل داده) و Matplotlib (برای تصویرسازی داده) سازگاری بسیار خوبی دارد. این امکان را میدهد تا با استفاده از ابزارهای دیگر، فرآیند تحلیل داده و توسعه الگوریتمهای یادگیری ماشین را بهبود بخشید.
- ارزیابی مدل: Scikit-Learn ابزارهایی برای ارزیابی مدلهای یادگیری ماشین ارائه میدهد. شما میتوانید با استفاده از این ابزارها، عملکرد مدلهای خود را بر اساس معیارهایی مانند دقت، بازخوانی و دقت پیشبینی بررسی کنید.
- پیشپردازش داده: Scikit-Learn ابزارهای متنوعی برای پیشپردازش دادهها ارائه میدهد. شما میتوانید با استفاده از این ابزارها، دادهها را تمیز کنید، ویژگیها را استخراج کنید و دادهها را برای استفاده در الگوریتمهای یادگیریماشین آماده کنید.
- تنظیم پارامتر: Scikit-Learn امکان تنظیم و بهینهسازی پارامترهای مدلهای یادگیری ماشین را فراهم میکند. این قابلیت به شما اجازه میدهد تا با استفاده از ابزارهای موجود در کتابخانه، پارامترهای مدل را بهینه کنید و عملکرد مدل را بهبود بخشید.
- پشتیبانی از تقسیمبندی داده: Scikit-Learn ابزارهایی برای تقسیمبندی داده به صورت تصادفی یا با استفاده از روشهای خاص مانند تقسیمبندی متقابل (Cross-Validation) را فراهم میکند. این قابلیت به شما امکان میدهد دادهها را به صورت صحیح تقسیم کنید و از روشهای ارزیابی معتبر برای مدلهای خود استفاده کنید.
- پشتیبانی از تعداد زیادی مسئله: Scikit-Learn قابلیت پوشش گستردهای از مسائل یادگیری ماشین را داراست، از جمله طبقهبندی، رگرسیون، خوشهبندی، تشخیص نمونههای نادر، تحلیل دادههای زمانی و غیره. بدین ترتیب، شما میتوانید با استفاده از Scikit-Learn برای حل انواع مسائل یادگیری ماشین بهرهبرداری کنید.
این فقط چند ویژگی از Scikit-Learn هستند و این کتابخانه دارای بسیاری از قابلیتهای دیگری است که از آنها میتوانید در فرآیند توسعه و تحلیل دادهها استفاده کنید.
میتوانم با استفاده از Scikit-Learn دادههای خود را تصویرسازی کنم؟
بله، میتوانید از Scikit-Learn برای تصویرسازی دادههای خود استفاده کنید، اما برای تصویرسازی دادهها باید از کتابخانههای دیگری مانند Matplotlib یا Seaborn نیز استفاده کنید. Scikit-Learn به تنهایی یک کتابخانه برای تصویرسازی نیست، اما با اتصال آن به کتابخانههای دیگر، میتوانید دادههای خود را تصویرسازی کنید.
به عنوان مثال، میتوانید از کلاس datasets در Scikit-Learn برای بارگیری مجموعههای دادههای آموزشی استفاده کنید و سپس با استفاده از کتابخانه Matplotlib یا Seaborn، نمودارها و تصاویر مختلفی را بر اساس دادهها رسم کنید.
در ادامه یک نمونه کد آورده شده است که نمودار رگرسیون خطی را برای دادههای دو بعدی رسم میکند با استفاده از Scikit-Learn و Matplotlib:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# تولید دادههای آموزشی
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# مدل رگرسیون خطی
model = LinearRegression()
model.fit(X, y)
# پیشبینی و تصویرسازی نتایج
y_pred = model.predict(X)
plt.scatter(X, y, color='blue')
plt.plot(X, y_pred, color='red', linewidth=2)
plt.xlabel('X')
plt.ylabel('y')
plt.show()در این مثال، ابتدا دادههای آموزشی به صورت دستی تولید شده و سپس یک مدل رگرسیون خطی با استفاده از کلاس LinearRegression در Scikit-Learn آموزش داده میشود. سپس با استفاده از مدل آموزش دیده، پیشبینی صحیح را برای دادههای آموزشی انجام میدهیم و نمودار رگرسیون خطی را به همراه نقاط داده رسم میکنیم با استفاده از توابع ارائه شده در کتابخانه Matplotlib.
با ترکیب قدرت Scikit-Learn و کتابخانههای تصویرسازی دیگر، میتوانید نمودارها و تصاویر مرتبط با تحلیل دادههای خود را ایجاد کنید.
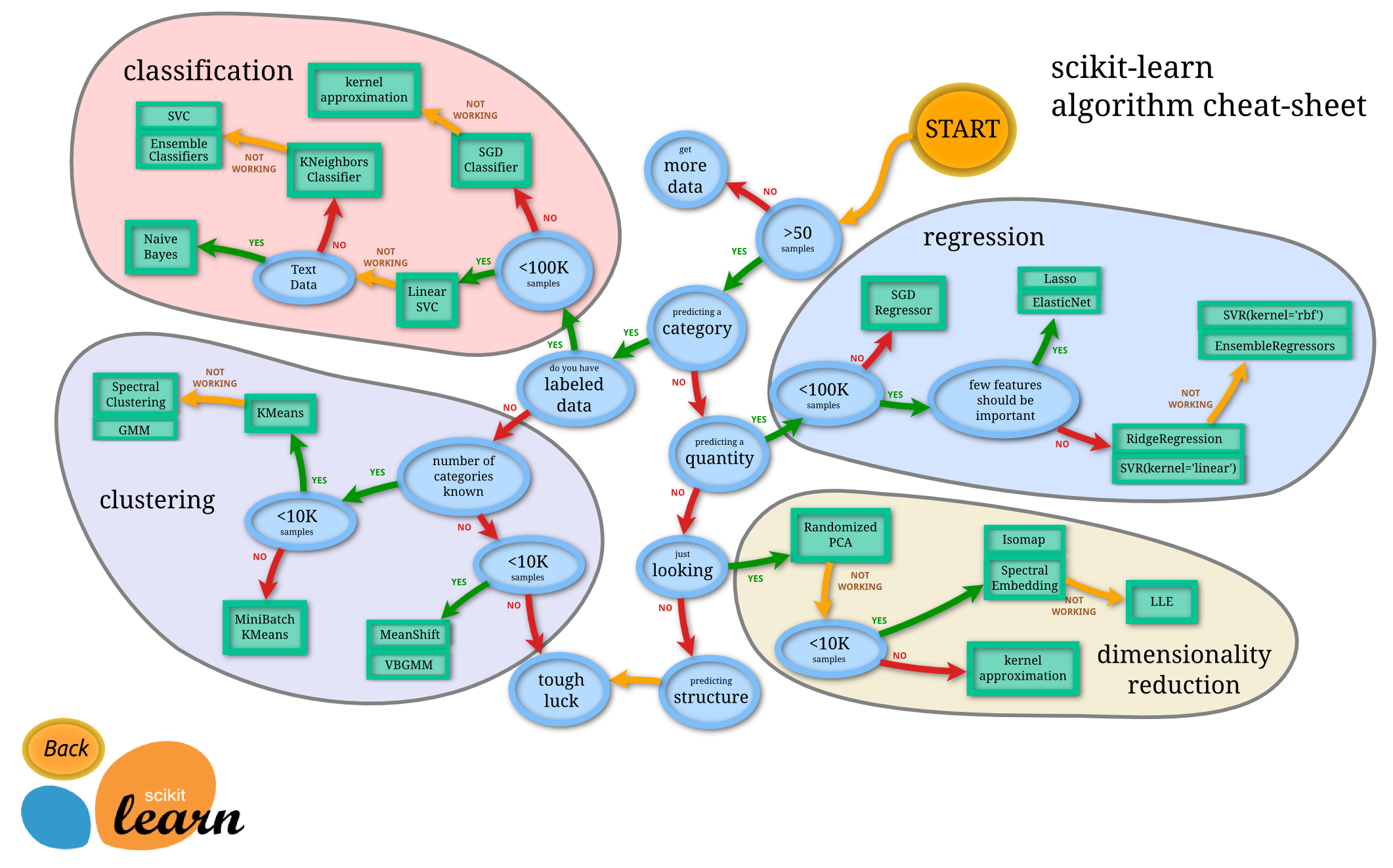
مراحل مدلسازی در Scikit-Learn
در این بخش، به توضیح فرایند مدلسازی در Scikit-Learn میپردازیم. این فرایند شامل چهار مرحله اصلی است که شامل بارگذاری داده، تقسیم داده، آموزش مدل و آزمون آن میشود. هر یک از این مراحل را به تفصیل بررسی خواهیم کرد.
بارگذاری داده Scikit-Learn
مرحله اول در فرایند مدلسازی در Scikit-Learn، بارگذاری داده است. Scikit-Learn از مجموعههای دادههای استانداردی پشتیبانی میکند که به آسانی میتوانید از آنها استفاده کنید. برخی از مجموعههای دادههای معروف در Scikit-Learn شامل Iris، Boston Housing، MNIST و Wine میباشند. همچنین، شما میتوانید دادههای خود را از فایلهای CSV، فایلهای Excel، پایگاه دادهها و منابع دیگر بارگیری کنید.
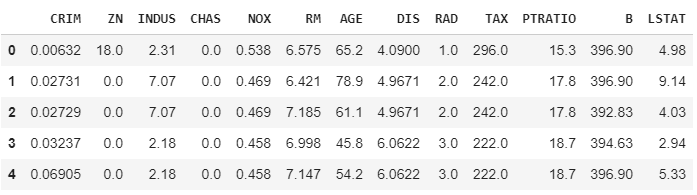
برای بارگذاری مجموعههای داده استاندارد در Scikit-Learn، میتوانید از توابعی مانند load_iris()، load_boston() و load_digits() استفاده کنید. به عنوان مثال، برای بارگذاری مجموعه داده Iris میتوانید از کد زیر استفاده کنید:
from sklearn.datasets import load_iris
# بارگذاری داده Iris
iris = load_iris()
# دسترسی به ویژگیها و برچسبها
X = iris.data # ویژگیها
y = iris.target # برچسبهادر این مثال، تابع load_iris() برای بارگذاری مجموعه داده Iris استفاده شده است. سپس با استفاده از ویژگی data، ویژگیها را در متغیر X ذخیره کردهایم و با استفاده از ویژگی target، برچسبها را در متغیر y ذخیره کردهایم.
اگر دادههای خود را از منابع دیگر بارگیری میکنید، باید از روشهای مناسب برای بارگذاری دادهها استفاده کنید. به عنوان مثال، میتوانید از توابعی مانند pandas.read_csv() برای بارگذاری دادههای CSV و یا توابع numpy.loadtxt() برای بارگذاری دادههای متنی استفاده کنید.
با بارگذاری دادهها در Scikit-Learn، میتوانید به مراحل بعدی فرایند مدلسازی، مانند تقسیم داده، آموزش مدل و ارزیابی آن، بپردازید.
مرحله دوم تقسیم مجموعه داده
در فرایند مدلسازی، تقسیم مجموعه داده به دو بخش آموزشی و آزمون (و گاهی اوقات بخش اعتبارسنجی نیز) بسیار مهم است. این کار به ما اجازه میدهد تا مدل را روی بخش آموزشی آموزش داده و سپس روی بخش آزمون ارزیابی کنیم. در Scikit-Learn در پایتون، میتوانید از تابع train_test_split استفاده کنید تا مجموعه دادهها را به صورت تصادفی به دو بخش آموزشی و آزمون تقسیم کنید.
در ادامه نمونهای از استفاده از تابع train_test_split را نشان میدهم:
from sklearn.model_selection import train_test_split
# جدا کردن ویژگیها و برچسبها از مجموعه داده
X = dataset.drop('target', axis=1)
y = dataset['target']
# تقسیم داده به بخش آموزشی و آزمون
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)در این مثال، X و y به ترتیب ویژگیها و برچسبها را نشان میدهند. تابع train_test_split دو بخش از دادهها را به صورت تصادفی جدا میکند. آرگومان test_size نسبت بخش آزمون را نشان میدهد و در مثال بالا برابر با ۰.۲ است، به این معنی که ۲۰% از دادهها به بخش آزمون اختصاص مییابد. آرگومان random_state نیز برای تعیین یک بذر تصادفی استفاده میشود تا تقسیم دادهها در هر بار اجرا قابل تکرار باشد.
آموزش مدل
پس از انجام مراحل پیشپردازش داده و تقسیم مجموعه داده، میتوانید مدل خود را آموزش دهید. در این مرحله، شما از یک الگوریتم مدلسازی خاص استفاده میکنید. Scikit-Learn در پایتون به عنوان یک کتابخانه معروف برای مدلسازی با الگوریتمهای مختلف شناخته میشود. در زیر نمونهای از فرایند آموزش یک مدل با استفاده از Scikit-Learn را نشان میدهم:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# جدا کردن ویژگیها و برچسبها از مجموعه داده
X = dataset.drop('target', axis=1)
y = dataset['target']
# تقسیم داده به بخش آموزشی و آزمون
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ساخت نمونه از مدل
model = LogisticRegression()
# آموزش مدل با استفاده از دادههای آموزشی
model.fit(X_train, y_train)
# ارزیابی عملکرد مدل روی دادههای آزمون
accuracy = model.score(X_test, y_test)در این مثال، از الگوریتم Logistic Regression استفاده شده است. ابتدا دادهها را به بخش آموزشی و آزمون تقسیم میکنیم و سپس یک نمونه از مدل Logistic Regression ایجاد میکنیم. سپس با استفاده از دادههای آموزشی، مدل را آموزش میدهیم (model.fit(X_train, y_train)) و در نهایت عملکرد مدل را با استفاده از دادههای آزمون ارزیابی میکنیم (model.score(X_test, y_test)).
میتوانید الگوریتمهای دیگری را برای مدلسازی استفاده کنید؟
بله، در Scikit-Learn در پایتون میتوانید از الگوریتمهای مدلسازی مختلفی استفاده کنید. Scikit-Learn به عنوان یک کتابخانه گسترده و قدرتمند، الگوریتمهای متنوعی را برای مسائل مختلف مدلسازی در اختیار شما قرار میدهد. در زیر چند نمونه از الگوریتمهای معروف را برای مدلسازی در Scikit-Learn ذکر میکنم:
- درخت تصمیم (Decision Tree):
DecisionTreeClassifierوDecisionTreeRegressor - ماشین بردار پشتیبان (Support Vector Machine):
SVCوSVR - بایس کند (Naive Bayes):
GaussianNBوMultinomialNB - شبکه عصبی (Neural Network):
MLPClassifierوMLPRegressor - رگرسیون خطی (Linear Regression):
LinearRegression - رگرسیون لجستیک (Logistic Regression):
LogisticRegression - رگرسیون رندوم جنگلی (Random Forest Regression):
RandomForestRegressor - رگرسیون گرادیانی تقویت شده (Gradient Boosting Regression):
GradientBoostingRegressor - خوشهبندی کامنها (K-Means Clustering):
KMeans - و بسیاری دیگر…
هر الگوریتم مدلسازی دارای پارامترهای خاص خود است که میتوانید آنها را تنظیم کنید. همچنین، Scikit-Learn امکاناتی برای ارزیابی مدلها و انجام تنظیمات مربوط به الگوریتمها نیز فراهم میکند. برای اطلاعات بیشتر درباره الگوریتمها و استفاده از آنها در Scikit-Learn، میتوانید به مستندات رسمی Scikit-Learn مراجعه کنید.
آموزش پیادهسازی SVM در Scikit-Learn
برای پیادهسازی الگوریتم ماشین بردار پشتیبان (SVM) در Scikit-Learn، میتوانید از کلاس SVC برای مسائل دستهبندی و از کلاس SVR برای مسائل رگرسیون استفاده کنید. در ادامه، یک نمونه کد برای پیادهسازی SVM در Scikit-Learn را نشان میدهم:
from sklearn.svm import SVC
# جدا کردن ویژگیها و برچسبها از مجموعه داده
X = dataset.drop('target', axis=1)
y = dataset['target']
# ساخت نمونه از مدل SVM
model = SVC()
# آموزش مدل با استفاده از دادههای آموزشی
model.fit(X_train, y_train)
# پیشبینی برچسبها برای دادههای آزمون
y_pred = model.predict(X_test)در این مثال، از کلاس SVC استفاده میکنیم تا یک نمونه از مدل SVM را ایجاد کنیم. سپس با استفاده از دادههای آموزشی، مدل را آموزش میدهیم (model.fit(X_train, y_train)) و سپس با استفاده از مدل آموزش دیده، برچسبهای پیشبینی شده را برای دادههای آزمون محاسبه میکنیم (y_pred = model.predict(X_test)).
برای ارزیابی دقت مدل SVM، میتوانید از معیارهای ارزیابی متداولی مانند دقت (Accuracy)، ماتریس درهمریختگی (Confusion Matrix) و گزارش کلاس (Classification Report) استفاده کنید. در Scikit-Learn، این امکانات در کلاس metrics قرار دارند. در زیر یک نمونه کد برای ارزیابی دقت مدل SVM با استفاده از دادههای آزمون (X_test و y_test) را نشان میدهم:
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# پیشبینی برچسبها برای دادههای آزمون
y_pred = model.predict(X_test)
# محاسبه دقت مدل
accuracy = accuracy_score(y_test, y_pred)
print("دقت: {:.۲f}".format(accuracy))
# محاسبه ماتریس درهمریختگی
cm = confusion_matrix(y_test, y_pred)
print("ماتریس درهمریختگی:")
print(cm)
# گزارش کلاس
cr = classification_report(y_test, y_pred)
print("گزارش کلاس:")
print(cr)در این مثال، ابتدا با استفاده از مدل آموزش دیده، برچسبهای پیشبینی شده را برای دادههای آزمون محاسبه میکنیم (y_pred = model.predict(X_test)). سپس با استفاده از معیارهای ارزیابی مختلف، از جمله دقت (accuracy_score)، ماتریس درهمریختگی (confusion_matrix) و گزارش کلاس (classification_report)، عملکرد مدل را ارزیابی میکنیم و نتایج را چاپ میکنیم.
استفاده از این امکانات به شما کمک میکند تا دقت و عملکرد مدل SVM را به طور جامع بررسی کنید و بتوانید در صورت نیاز تنظیمات مدل را بهبود دهید.
یک مثال از استفاده از تخمینگرهای کتابخانه Scikit-Learn برای مدلسازی
به طور کلی، کتابخانه Scikit-Learn قابلیت مدلسازی در تنوعی از مسائل مانند دستهبندی، رگرسیون، خوشهبندی و غیره را داراست. در اینجا یک مثال از استفاده از تخمینگرهای کتابخانه Scikit-Learn برای مسئله دستهبندی را بررسی میکنیم:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# بارگیری مجموعه داده Iris
data = load_iris()
X = data.data
y = data.target
# تقسیم دادهها به مجموعههای آموزشی و آزمون
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ساخت یک نمونه از مدل SVM
model = SVC()
# آموزش مدل با استفاده از دادههای آموزشی
model.fit(X_train, y_train)
# پیشبینی برچسبها برای دادههای آزمون
y_pred = model.predict(X_test)
# محاسبه دقت مدل
accuracy = accuracy_score(y_test, y_pred)
print("دقت مدل: {:.۲f}".format(accuracy))در این مثال، از مجموعه داده Iris استفاده میکنیم که یک مجموعه دادهی معروف در دستهبندی گلها است. ابتدا دادهها را بارگیری کرده و سپس آنها را به دو بخش آموزشی و آزمون تقسیم میکنیم. سپس یک نمونه از مدل SVM را تعریف کرده و با استفاده از دادههای آموزشی، مدل را آموزش میدهیم (model.fit(X_train, y_train)). سپس با استفاده از مدل آموزش دیده، برچسبهای پیشبینی شده را برای دادههای آزمون محاسبه میکنیم (y_pred = model.predict(X_test)). در نهایت، با استفاده از معیار دقت (accuracy_score)، دقت مدل را محاسبه و چاپ میکنیم.
این مثال نشان میدهد که چگونه از تخمینگرهای کتابخانه Scikit-Learn برای مدلسازی و پیشبینی در یک مسئله دستهبندی استفاده میشود.
جمع بندی: آیا Scikit-Learn کاربری است؟
در این مقاله، ما برای شما Scikit-Learn و مفاهیم آن را معرفی و آموزش دادیم. برای استفاده از این کتابخانه، آشنایی با کتابخانههای Numpy، Pandas و matplotlib ضروری است تا بتوانید با ساختار دادههای آنها کار کنید. این کتابخانه قادر است مدلهای مختلفی را با استفاده از تخمینگرهای خود (fit) تنظیم کند و با API خود امکان آزمون آن را بر روی دادههای آزمون فراهم میکند.
امیدواریم که این مقاله برای شما مفید بوده باشد و از آن بهرهمند شوید. ما خوشحال میشویم اگر نظرات و تجربیات خود را با ما به اشتراک بگذارید.



